FastFrida
FastFrida
January 2025 - Present
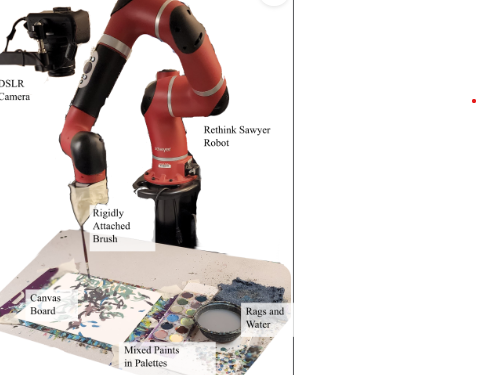
Reinforcement Learning Robot Painter
Master's Student Research
CMU Robot Intelligence Group (BIG)
Skills applied:
- Reinforcement Learning
- Curriculum Learning
-
Soft Actor Critic
- Computer Vision
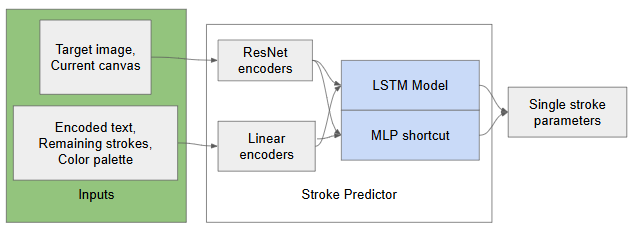
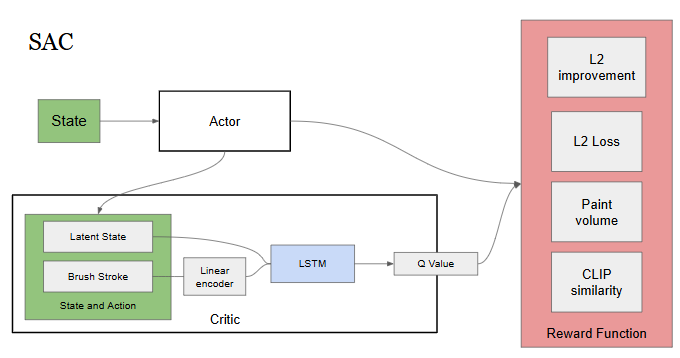
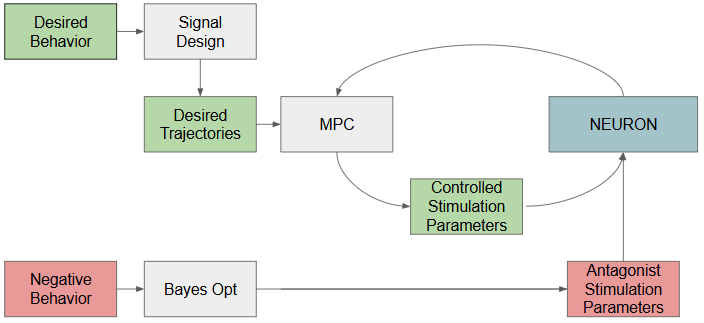
FastFRIDA is a reinforcement learning-based system that translates images and text descriptions into expressive brushstroke sequences for robotic painting. The project builds on the FRIDA framework, replacing its slow optimization loop with a learned policy trained via imitation learning and Soft Actor-Critic (SAC). The model observes a canvas, target image, prompt, color palette, and stroke count, and outputs a probabilistic stroke distribution at each timestep. A custom reward function balances CLIP similarity, pixel accuracy, and paint efficiency. While SAC requires careful initialization from imitation learning, the project demonstrates early-stage results and lays the foundation for real-time robotic painting with future improvements including transformer-based models and causality-aware architectures.
The Actor structure is on the left and the SAC training structure is on the right.